
Journal of Law, Information and Science

|
|
Home
| Databases
| WorldLII
| Search
| Feedback
Journal of Law, Information and Science |
|
SURENDRA DAYAL[1] and ROBERT N. MOLES[2]
This article concludes that it is possible to use useful and useable information systems in the legal sphere. However, this process is improved greatly if the client for whom the system is being designed for is intimately involved at the design stage. The use of hypertext is also recommended so that the user can be directed through the volumes of material which can form part of any legal issue. The authors consider that information systems must contain a subjective viewpoint and that the search for objectivity is unattainable. They are of the opinion that this approach places responsibility for decision about meaning squarely on the shoulders of the individuals accountable for those decisions.
This article follows on from two earlier articles which have appeared in this Journal.[3] Whilst we do not intend to repeat what has been said before, a brief summary of the position to date might be helpful to provide a backdrop for the material in this article.
In the first article, we pointed out that some people, working in the area of expert systems and law had not, in our view, been careful enough about the methodology which they had employed. This stemmed from their rather naive approach to questions of interpretation and meaning within the legal framework.
• We showed how computer science students were set to work to encode the meaning of statutes, without any understanding of the context within which those statutes were enacted or applied.
• We also saw how the researchers assumed that legal materials were made up of a number of discrete entities (statutes, cases, regulations) which could be manipulated independently of each other - the "law is rules" view.
• We saw how they thought that either the words, or the rules, could be said to have an unambiguous meaning.
• We showed how difficult it was to follow their process from source documents to knowledge base in the discussion of isomorphism.
We explained that the difficulties arose because the researchers had no experience of the application domain, and were basing their work on a view of the objectivity of meaning in language which has been rejected by a significant proportion of philosophers, linguists, psychologists and sociologists for many years now. We preferred the view which is summed up in the expression the "social construction of reality".
In responses to that article, some critics, whilst being careful to state that they could agree with many of the criticisms, were nevertheless of the view that the arguments against objectivity were not convincing, and that theory (or jurisprudence) was not going to assist us to settle the issue one way or the other.
In the second article, we responded by further explaining the arguments against objectivity, illustrating the variability of possible meanings of legal propositions, by looking to the particular example of contract law. The argument here, was to the effect that legal propositions (or rules) are the products of two forces -
1. the factual situation from which they emerge,
2. the argumentative strategy in accordance with which they are formed.
Neither of these aspects are, of course, independent of the other - it can clearly be seen that different argumentative strategies will take different views of the facts in any case. The social construction of reality applies as much to the construction of the "facts" of any case as it does to the legal propositions themselves.[4] It was these two aspects, in particular, which we felt were being ignored by some expert systems builders who felt that legal propositions could be referred to in the abstract and without specifying their contextual framework.
Of course, there was nothing particularly new in the points which we were putting forward. We were, in fact taking up a theme which has been argued at great length in legal theory - in earlier years - by the American Realists (sometimes referred to as "rule sceptics" and "fact sceptics") and by the Scandinavian Realists. More recently some of these issues have been taken up and elaborated by Feminist and Critical Legal Studies scholars as well as many others who would not see themselves coming within these groups. Indeed, far from being an extreme point of view, the first of the above points, is in fact affirmed in all of the standard books on precedent and introductory legal method. The standard view of the doctrine of precedent usually states that the ratio decidendi (the authoritative part of the case) is the product of the material facts of the case together with the legal proposition as stated by the judge:
In its very simplest form, the ratio of a case is the judge's decision on the issue raised by the facts.[5]
The statements by a judge which are not sufficiently related to the facts of the case are regarded as obiter dicta and, as such, are said to be not binding in future cases. The standard technique for avoiding a troublesome precedent is to argue that the facts of the instant case are different from those of the precedent case, and therefore the precedent is "distinguished", by its relationship to the facts of the two cases.[6]
However, we were concerned that our critics thought that what we were saying appeared to be negative in relation to the potential for development in this area. This is far from being the case. Indeed, both of the current authors are engaged in significant systems developments. Rather, our concern was twofold:
1. We wished to point to basic aspects of legal interpretation which we felt were insufficiently appreciated by some systems designers.
2. We then attempted to place these views within a sounder and broader theoretical context, and in such a way that they might be of assistance to those involved in designing computer based systems.
The important thrust of our argument was that what you observe is as much a matter of where you are coming from, as it is of what you are looking at. The views of which we have been critical have tended to miss out the "where you are coming from" part altogether. This is why they believe that rules can be detached from their factual context, and then bandied about in the abstract and without being affected by the change of context or by an alteration in the argumentative strategy. This was particularly noticeable in the discussion of isomorphism which we looked at in some detail in the first article, but was also clearly stated to be a working assumption by Zeleznikow and Hunter.[7]
In opposition to this, we suggested that the knower and the known are too intimately connected to be separated in this way. Therefore we agreed with Ronald Stamper that an effective system would need to incorporate, as part of its design, an account of the person or persons whose knowledge it is that is being modelled.[8] In this way the system designer deals with the problem of "responsibility" which Stamper referred to. A corollary is that when we attempt to move from a legal source text to a knowledge base, which is the rule-based embodiment of the expert's knowledge, all of the steps in the transition from one to the other, must be open, and verifiable to the expert whose knowledge is being modelled. To date, system developers have largely ignored the importance of maintaining an open process of knowledge base construction, which specifically incorporates the knowledge of an expert as the instantiation of a particular point of view.
Having acknowledged that the issues which Stamper addresses have to be considered by expert systems designers, we undertook to give an account of production systems which do just that.
In the second article, we explained that one of the reasons for the problems which have arisen in this area is that some researchers have an inconsistency in their position. The logic programmers said that they were not attempting to model legal reasoning, and our critics said that legal expert systems were really nothing more than glorified check lists or indexes. Yet at the same time, both groups stated that
such systems [the systems they are developing] can derive answers from rules when faced with given fact situations.[9]
We pointed out that in our view, this was going considerably beyond the "check list" view, and did indeed require an understanding of legal reasoning. We felt that these confusions arose because some of the researchers in this area were none too clear as to what it was that they were trying to do. Were they attempting to develop systems which would determine the outcome of cases or, more modestly, to be of assistance to people whose job it was to determine the outcome of cases? Whilst sometimes they claimed that they were only engaged in the latter, more modest exercise, it appeared to us, from statements such as the above, that they did indeed think that the former, and more ambitious activity, was not only a possibility, but indeed something that they were pursuing.
The second major issue which we raised then, was the distinction between decision support systems and decision making systems. The former would include indexing systems or procedural checklists. The latter, systems which lead the user into a more dependent relationship with the system. It may well prove to be the case that what these other researchers have been saying with regard to decision making, amounts really to no more than decision support, or that what we describe as decision support would, by them, be regarded as decision making. Either way we feel that the following points should be made.
Greater clarification of the underlying methodology involved with computer systems, when compared to that which is undertaken by the lawyer, will show that future research into applications in the legal domain should be focused on decision support systems, rather than systems which actually attempt to emulate legal reasoning, or to produce legal outcomes. This does not mean that we should not attempt to examine and expand the utility of the computer revolution for lawyers. It merely means that we should focus our attention on areas which have elements of those tasks which computers can adequately deal with.
Computers can of course manipulate symbols. Given a set of symbols, together with rules for transforming those symbols, the computer will produce those transformations at great speed and with unfailing accuracy. This means that one can set the computer to work in situations where those symbol transforming exercises are regular and predictable and where the appropriate transformations may be known in advance. Richard Susskind has emphasised the possibility that an expert system may be used in highly constrained, specific areas of law[10]. In our view, even if it were meaningful to speak of compartmentalising law in this way (which it is not) this does not allow for the fact that the symbol transformations involved when moving from source documents (precedents and statutes) to knowledge base, are more complicated and unpredictable than he allows for. This is especially so when we are talking of reasoning within an adversarial system.
In a sense the whole skill of advocacy is innovation and adaptation. When Joseph Weizenbaum first showed his ELIZA system (which mimic-ed the relationship between a patient and a psychotherapist) to psychiatrists, some of them took enthusiastically to the idea of the "rule directed therapist" - psychotherapy by computer. Weizenbaum says that he was shocked to find what little insight these therapists had into their own area of expertise. That they could so readily assume that the task in any particular case could be rule directed goes against the fundamental nature of the enterprise in which they are supposed to be engaged, and which requires empathy and adaptation to the particular circumstances of any case.[11]
Machines can provide a useful function, but it is unwise to claim that any legal knowledge base in our machine is equal in meaning to the source documents from which it is derived. It is easy to forget that lawyers do not start with "source documents" but with people's problems. Lawyers also have regard to many factors which are not contained within any documents - the informal or tacit knowledge which Stamper refers to. That informal context will be very important in helping to identify anything which might be regarded as "source documents'". But even when we have such things, an interpretation of those source documents must be adopted and someone must take responsibility for that interpretation - there can be no knowledge without a knower. In the adversarial system, this aspect renders the matter almost a futile task, unless we are content to deal simply with broad generalisations. The skill of lawyers in such situations is to come up with a point of view that serves their client's interests. They are not interested in taking a supposedly "objective" view of any fact situation or document.
In the recent Rodney King trial in Los Angeles, defence counsel were faced with the difficulty that their clients were recorded on video tape - the images were more graphic than any words could have been, and many would have thought that those images "spoke for themselves" - carried with them a clear and incontrovertible meaning. Yet when counsel showed them to the jury - a frame at a time - just as we might take a word at a time, their meaning began to change. At that level of examination, each frame began to lose its sense of brutality. If the officers were entitled to strike a blow to restrain King, which specific blow was the first one to be "unauthorised". Counsel then made very specific the interpretative framework which they wished the jury to use - King was in charge all along - he brought it all upon himself. Perhaps one can see that working with this framework (or assumption), the observable manifestations take on a whole new meaning. The actual observations have not changed - but they are now seen "in a different light". When the charges moved from the State to the Federal court, defence counsel utilised yet another interpretative framework or assumption. On this occasion, it was not so much that King was "in control" but that the officer was "unconscious" at the time that he was assaulting King. Of course, he was moving around a lot, and certainly appeared to be striking blows, but he was, said the lawyer, unconscious - excitement, fear, adrenalin - everything happened so quickly - the officer simply was "not conscious" of what was happening.
No doubt many would find these interpretations surprising, but as well as being successful - which they were - they do highlight the fact that our ordinary interpretations carry with them a lot of assumptions too. These ingenious arguments bring to mind the fact that our ordinary interpretations would probably be based on assumptions that King was not in charge and that the officer was conscious. We may even have thought them to be so obvious that they were not worth mentioning - but they were there nevertheless. So too with interpretations of words alone, the multiplicity of possible interpretations regarding any piece of language cannot be constrained unless a framework is provided within which the interpretation of that language takes place. The difficulty is, that if we articulate the framework in words, then those words will also require a framework within which they are to be interpreted. This is a common problem with the attempt to clarify meaning by using definitions. Are the defining words themselves to be defined?
What this means is that we can only get so far by using abstract symbols (words). Exchanging some words for others only shifts the problem (of meaning) but does not resolve it. Ultimately those symbols have to be placed within the context of the world within which those meanings make sense. Susskind appreciated the general significance of this problem but failed to appreciate this particular point. When he referred to the importance of legal heuristics, (informal knowledge) he noted that unfortunately they are often not written down, and are therefore relatively inaccessible. He did point out that this is not always so, as in Scotland, for example, the Sheriff courts have books containing rules of practice and procedure. Susskind's answer is therefore to look forward to the day when this necessary informal knowledge becomes formalised - failing to appreciate the point made by Stamper (and some years earlier by Michael Polanyi)[12] that formalisations will always - and necessarily - depend upon an informal (and not formalisable) context. Unless expert systems developers get to grips with this aspect of epistemology, their attempts to "write down" the expertise of experts will be doomed to failure, because the key to understanding the meaning of what has been written down will be lost. We will still need to know who are the "experts" and what are their concerns? It may be that this is the problem which is not addressed by the CYC Project which is attempting to provide a massive database within which all the "commonsense knowledge" will be placed. No doubt feminists and critical legal studies scholars will want to know whose commonsense will be afforded pride of place.
It follows, then, that the only way in which this problem can be solved is to break out of the circle of abstractions. To do as Stamper suggests and link the knowledge with the person or persons whose knowledge it is said to be. Taking the lesson of research which has been conducted to date, useful systems may be built within a framework that acknowledges and accounts for the multiplicity of meaning found in any natural language document. We would like to suggest that greater potential for building production systems can be found by looking to the different approach which has been adopted in some of the legal research and decision support systems which have been developed in Australia. As examples of this work we will look to some systems which were constructed in Australia by SoftLaw Corporation.
This article focuses on the current state of technology, in particular relating to hypertext retrieval systems, and rule-based expert systems. We illustrate how such technology can be used to provide useful and useable decision support systems, within a framework that does not ignore the fluid nature of natural language.
Since the attempted introduction of computerised technology into the legal domain, those working in the field have marked a distinction between various types of legal systems. One of the fundamental distinctions has always been between those systems which aid in retrieval of legal material, and those systems which assist the user to make decisions within the legal framework.[13] This distinction will often be blurred. Decision support systems will incorporate a measure of retrieval characteristics, and any effective retrieval systems must offer some sort of conceptual analysis within which to provide information:
The legal user needs an information retrieval system based on efficient semantic structures capable of analysing [the] request, comparing it with the database documents and identifying those texts or subparts of them which are relevant to [the] search.[14]
A good example of a system explicitly integrating decision support with text retrieval tools is the Datalex Legal Workstation.[15] Most of the decision support systems produced by SoftLaw incorporate both an expert system and a hypertext component. STATUTE Expert, SoftLaw's standard construction tool for expert system development supports the following sort of interface:
Diagram 1: Standard Expert System Question Screen
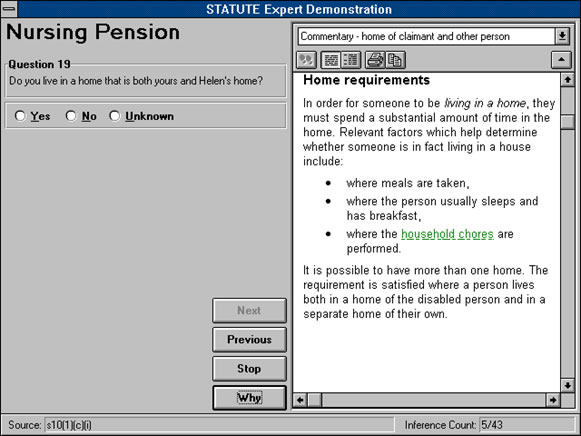
The question on the left is generated from the expert system, while the textual assistance on the right is provided in hypertext. There has been some attention devoted of late to this type of incorporation of a hypertext retrieval system into a legal expert system.[16] This article examines why it is not only desirable but necessary to incorporate a hypertext retrieval system into any serious decision support system intended for production use. Furthermore, it analyses some of the considerations that this raises when constructing both the expert and the hypertext components of any substantial application. In Parts II and III we examine some of the fundamentals of hypertext and expert system construction in the legal domain. Examples are taken from an application which incorporates both hypertext and expert systems operating as separate components, and operating in conjunction with one another.
The focus of this article is still on rulebased systems. The shift in emphasis found in this paper from previous papers describing legal expert systems is subtle but has profound implications for the practical development of working systems.
The previous focus has been on finding discrete areas of the law which might be amenable to modelling with a computer. An example is the set of criteria proposed by Susskind, aimed at finding a suitable subset of the vast array of legal doctrine to model.[17] Systems predicated on such criteria focus on the provision of assistance in the adversarial arena.[18] The difficulty with trying to narrow down an area of the law in such a manner is that the good advocate always attempts to go beyond the confines of a narrow set of legal doctrine. In the most common setting, the advocate will try and argue by analogy in order to escape what might seem to be the solid confines of the existing statute and case law "in that area".
The further difficulty with attempting to narrow down the applicable law to a finite domain is the informal or tacit knowledge which goes into the interpretation of that area of law. Susskind refers to this as "heuristic knowledge" and recognises that any computing system must contain a large amount of this knowledge to function.[19] Attempting to model this knowledge is difficult since its subjective aspects can never be fully resolved. We are faced with a recursive problem, because for every set of concepts written down to explain another set, a yet further set will be required in order to interpret the new written material.
Both of these difficulties with the attempt to "objectively" model legal knowledge can be overcome, but we need to combine a number of strategies in order to do it. The source of the difficulties lies in the fact that by focussing on the area of law itself, or on the heuristics which are used to interpret that law, we ignore the more fundamental issue of "whose interpretations are we modelling?" The problem is not whether we can write the concepts down, but whether we can account for them by taking a position in respect of each of them. To really know what we should be modelling, we must identify the person or group whose tacit knowledge and whose point of view it is that we wish to take up. We doubt whether this can be done effectively within the adversarial framework, but it can certainly be done at an organisational level. A group of people, whose task it is to administer the law, can be used to provide that point of view. That individual or group can then determine which transformations between the source material and knowledge base are in accordance with the tacit knowledge underlying their approach to the body of law.
In the past, the importance of the tacit knowledge underlying the interpretation of an area of law has been recognised, although the extent of its influence, and our ability to capture it symbolically, have been considerably underrated.[20] Yet our view is that it is this - the point of view taken - which drives the whole process of interpretation. The primary source material becomes just one element, amongst many others, in a system which is based on the adoption of a point of view and a process for implementing that point of view.
The new approach articulates and adopts a framework in which to interpret the law. The approach allows a client to say "this is what I want to model", and the technology can be used to implement this vision. The reasoning and the logic imparted to the system then come from the analyst and the organisation itself - someone in the decision making environment always has responsibility for an interpretative decision.
Such an approach has certain corollaries which remove some of the fundamental obstacles with trying to find one objective meaning for the law, but it does, as we pointed out earlier in our discussion of Stamper's work, introduce extra complexity in the underlying implementation of the knowledge base:
1. There is less emphasis on trying to narrow down the applicable legal doctrine in an objective way. What becomes important is the set of criteria adopted by the organisation in their approach to interpreting the area of the law.
2. There is still a great emphasis on capturing the heuristic and tacit knowledge which must accompany the system. However, elucidating such knowledge no longer becomes a process of swimming in a morass of possibilities. A clear stance is taken which can be used to resolve different heuristic approaches.
3. The process of getting from the legal sources to a knowledge base is still one of symbol transformation.[21] In the first instance, an attempt is made to make a syntactic transformation from the source material to a core legal knowledge base. Inevitably at some points issues of meaning arise, but they can be resolved by the organisation for whom the system is built. Secondly, the knowledge base is shaped by the specific approach and knowledge of the client. In order to achieve both of these steps in a manner consistent with the client's needs, the source materials must be modelled in a way which is meaningful both to the person wanting the system, and to the developer. This is how we can ensure that it is actually the client's point of view which is captured by the system.
4. The semantic analysis in the system does not avoid the incurably open textured nature of language. Rather than avoiding the question of multiple interpretations, we must try and deal with them by constraining the meaning of the language to that adopted by the client.
The implementation difficulties introduced by corollaries 3 and 4, and some solutions, will be explained in part III.
The concept of hypertext has been around for some time.[22] However, with the advent of expert systems technology and the proliferation of legal documents, it is only now achieving prominence in the legal environment.[23] Here we describe some of the basic features common to any hypertext system, and an example of a production-use hypertext system.
In most hypertext retrieval systems, the following functionality is provided:
The capacity to structure source material in a coherent way, by breaking the document up into conceptual blocks called "nodes".[24] Depending on the nature of the system, these nodes may be filled with text, graphics, images or audio data.[25]
The capacity to link from one portion of material to another by means of internal links. These links may take two forms:
(i) What are commonly referred to as "vertical links", which allow the developer to link a particular word called a "hotword" with a particular node or group of nodes,
(ii) What are conceptually "horizontal links", which allow the developer to cross-reference nodes. For example, one node might be defined as a particular provision of legislation, and another might be policy material on the given provision, while yet another might consist of a list of cases on the provision. Each of these nodes could be linked horizontally to one another.
A set of specific entry points into the system. These may take the form of a free text search,[26] or could be more conceptually based, such as through a subject index.[27]
The capacity to display a specific node for the user to view. This can either be achieved through the initial points of access into the system, or the internal links provided by hotwords.
Systems are available which provide these functions in a character-based environment - typically associated with an operating system like DOS.[28] Alternatively, developers may use the increasingly popular graphical operating environment - such as on a Macintosh[29] or in Microsoft Windows.[30]
Hypertext has recently been coming to the fore as one of the main vehicles for legal information retrieval.[31] It is a good text retrieval tool because it provides powerful methods of document presentation in the electronic medium, allowing:
structured text presentation,
access facilities to large bodies of text in electronic form,
indexing facilities for complex documents,
fast methods of linking large documents together in a coherent manner.
Legal documents are particularly well suited to conceptual retrieval rather than retrieval purely based on free text searches.[32] A free text search will depend very much on the user of the system having a very good knowledge of the field being researched, and will often result in:
(i) a disclosure of irrelevant documents,
(ii) non-disclosure of relevant material.[33]
The use of Hypertext to build legal retrieval systems allows both for text retrieval as well as conceptual indexing. Hypertext is particularly well suited to the legal environment, due to some of the inherent characteristics of legal documents:
Legal texts are densely cross-related, either expressly or by implication: cases interpret statutes; cases cite cases; definitions define terms used elsewhere in the same statute; regulations have as their source the provisions of a statute, and legal commentaries are usually a thicket of cross-references.[34]
Many of the concepts in hypertext are more easily seen by looking at an example of such a system. One of the research systems built by SoftLaw is a part of a comprehensive decision support tool which helps clerks in the relevant organisation to apply and administer the law relating to insurance for personal injury. Hypertext was used by the system in two ways. Firstly, it was accessed in conjunction with the expert system to provide source material and policy assistance for questions asked within the expert system.[35] Secondly, the hypertext formed a research system in its own right, providing access to the materials described in the next section.
There are three main types of source document used to produce the hypertext research system. These source documents are relatively standard in the administrative environment. They may be classed as primary and secondary:
The primary material in the system consists of the relevant Act (subsequently referred to as the Act) and associated regulations;
The secondary material in the system consists of
(i) the Policy Guide to the Act, written by the administering organisation to provide policy guidelines on the organisation's interpretation of the Act,
(ii) the Procedures Manual to the Act, written by the organisation to provide procedural guidelines on how to administer the Act.
These source documents represent approximately nine megabytes of source text, or about 4500 A4 pages.[36] As yet, there are very few cases on the new legislation, but the retrieval system is currently being extended to incorporate relevant case material, opinions, articles and case-notes. Diagram 2 shows the basic interface used by the research tool.
The hypertext was authored in STATUTE Hypertext, a hypertext viewing tool and associated development environment produced by SoftLaw (version 3.0 of the software has now been renamed to STATUTE E-Publish). Multiple windows can be opened on the screen, with links incorporated between related sections and words. Linked words appear highlighted in green and underlined, and explicit cross-references are accessed via one of the buttons on the top of the screen. The standard hypertext environment also incorporates navigational tools for the user which include:
standard text searching for words or groups of words,
a history of nodes visited so far,
the capacity to leave bookmarks at various points in the text to return to at a later stage.
Diagram 2: Standard Hypertext Retrieval System

Initial access to the hypertext retrieval system can occur in a number of ways:
For the inexperienced user, there is a subject index to the legislation and policy documents in the system (see the index shown in diagram 2). This was constructed using generic indexing software which is now provided with the authoring environment.
For a more experienced user, who has a better idea of the particular provision they are after, direct access to a given provision is available in one of two ways:
(i) through a list of provisions, which gives the heading of each provision and provides a link into any provision in the Act; or
(ii) through a section selector into which the user can enter the number of any legislative provision to view.
The decision support system. Every question posed within the system, and every point in the system which calls for user input provides direct entry into the hypertext system. The user is shown the relevant policy material and may toggle to view the particular legislative provision under investigation. Hotwords in the policy material appear underlined in green (in the screen capture they are the lighter underlined words in the text) and allow the user to navigate to relevant issues directly from within the decision support system.
Diagram 3: Decision Support System with Commentary Displayed in Hypertext
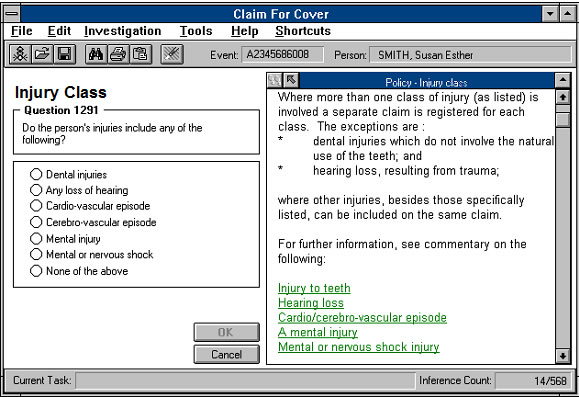
Where a hypertext retrieval system is being used in its own right, then there must be some means of quickly accessing a desired portion of the source text without having to search through large amounts of material. Free text and associated forms of retrieval (key word searches, etc.) are not always appropriate to the environment, since what is being presented to the user is knowledge in a structured form.
In the construction of hypertext retrieval systems, several basic issues are apparent:
1. To build a hypertext system which is useable and useful, it is not enough to merely take some text, shove it in the database and then attempt to impose upon it the internal referencing which is necessary in order to move within the system. The material must, itself, have been prepared with the structure in mind. Otherwise it will be more likely to confuse the user rather than to make things easier.
2. The cross-referencing methodology in any hypertext system must be consistent and user friendly. This cross referencing consists of two aspects:
(i) largely horizontal referencing between documents,
(ii) hierarchical referencing within one document.
3. The user must be given adequate initial access to the document, including indexes and entry points as described above.
Without due weight being given to structuring the hypertext system, the problem of "spaghetti text" occurs, with the user not knowing where they can go from any portion of the text, or indeed, where they are at any time.[37] The structure must be consistent and intuitive, so that the user can quickly become familiar with the sources of information available to them at any given time.
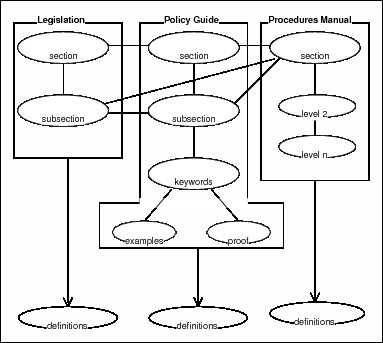
Since one of the key facets of the hypertext is that it provides structured access to source material, the source material must be written with this objective in mind. When preparing and writing the text for inclusion in a hypertext system, the documentation writers must have some understanding of the final structure which the system will have.
The basic structure of the system as it currently stands is set out in the following diagram. The horizontal links between documents are examples of node to node references between various portions of the document, while the vertical links within the same document are hotword links from keywords to portions of text.
Diagram 4: Standard Hypertext Retrieval System
One type of commonly used expert system architecture relies on the specification of rules of inference. This sort of system is characterised by the representation of knowledge as rules and facts, typically consisting of a knowledge base and an inference engine which allows logical deductions to be made from the knowledge base.
A pre-defined knowledge base can usually be used in conjunction with the inference engine for at least the following functions:
Given a particular fact to investigate, the system can search its memory and generate questions aimed at subsantiating that fact. In more sophisticated systems, uncertainty will also be handled, so it is possible to reach a conclusion that it might be possible to substantiate the given fact.
The system can provide a report explaining how the conclusion was derived in respect of any fact.
A modern rule-based system will typically include other functions,[38] such as a facility to provide explanations why a particular question is being asked of the user, the capacity to save investigations and return to them later, and backtracking facilities which allow the users of the system to retrace their steps.
Rule-based systems have often been classed as shallow, in the sense that rather than modelling underlying principles, processes or theories, they capture simple empirical associations. However, depending on the level of the expert whose knowledge the system is to capture, this will often be a matter of degree. Shallow rulebases can be constructed in which rules interact very little. On the other hand, there can be a web of inter-related concepts which are modelled in the system. The more complex the web, the deeper the knowledge in the rulebase.
Furthermore, with many of the more advanced rule-based systems, it is also possible to incorporate objects into the system, which have attributes associated with them. Such objects allow deeper world or heuristic knowledge to be captured, especially if it is possible to reason with such attributes. An example would be to represent the people "Bill" and "Ted" in the system, and give them a set of characteristics such as age, height, intelligence, etc. It is possible to have facts which are true of Bill but not of Ted, giving us context-sensitive knowledge. Thus we could say "Bill qualifies for unemployment benefit", which could be true at the same time as the statement "Ted does not qualify for unemployment benefit". If we then include the facility to reason based on the attributes held by the person we could make statements like "Bill cannot hold a driver's licence, because he is under the age of 16", or "Ted cannot go to university because he scored less than 50% on his final examination."
With a sophisticated system, there are several useful roles which can be fulfilled by rule-based systems in the legal area. Two such functions previously adverted to in the literature are procedural checklists[39] and facilities for reducing the logical complexity which must be dealt with by administrative decision makers.[40]
A rulebase can reliably be used as a platform for a "best-practices" approach to a business problem. When used in this fashion, the rules model the process which must be followed in order to guarantee at least a certain level of quality in decision making. Because the rulebase incorporates logic, this process can be "intelligent" in the sense that it can respond to changing facts situations. Furthermore, since the rulebase is followed slavishly by the computer, it is not possible to accidentally miss a step in the process. For example, we could have a simple high level rule which went as follows:
|
The review process for welfare benefits is complete if
option 1:
The person has been receiving welfare for 6 months without review;
and
The partial review process is complete; or
option 2:
The person has been receiving welfare for 12 months without review;
and
The full review process is complete
Otherwise conclude the review process for welfare benefits is not
complete.
|
This would then lead into lower level rules dealing with the requirements which must be fulfilled in order to fully complete the relevant processes.
Rules can also be used to handle logical complexity. Expert systems can offer substantial assistance in the application of legislation by guiding users through areas of logical complexity and asking all the questions required in order to make a determination on a given issue.[41] For example, a complex section of legislation might require a decision maker to fully consider the following:
I am investigating the issue of child support under section 11,
I must know the legal definition of support in section 2,
I should be aware of the definition of a child in accompanying legislation,
the provisions governing exceptions in part IV are relevant,
the department's guidelines on periods for which support is payable must be taken into account.
In each provision, there may be quite complex logic involved, and the logical interaction of the provisions may be substantial. Applying all of these interacting sources is not an easy task, especially when the primary decision maker typically has no formal legal training, and maybe inadequate office training. However, given a particular point of view, the office requirements can largely be automated, so that the decision maker is investigating the correct provisions and answering all of the pertinent questions.
An application in the administrative environment can fulfil both of these functions - ensuring procedural compliance, and handling logical complexity. Both of these functions are subject to the client - the administrative organisation - making decisions about how it wants to approach business problems and to interpret particular provisions. Because we are dealing with language, the process will inevitably involve interpretation and the making of decisions. The key is to keep the process open, and articulate each interpretative decision which is made. As long as these decisions are faithfully captured in the knowledge base, then the client organisation will have an application which is consistent with their point of view.
The primary tool of the law is language. Concepts are expressed as language, and communication is through language. This will be the case regardless of whether or not an expert system is being used to resolve the application of the legislation. Where an expert system applies rules to a set of facts, then the basic form of communication between the user and the machine will be through the user's response to queries. Based on the knowledge represented in the expert system, and according to how the user responds to given queries, the system can draw logical conclusions and report on how it arrived at them.
Because of this stage of interaction with the user, a developer of decision support systems must address more issues than those of mere logic. Dealing with some of the deeper issues of meaning within the legislation is unavoidable. Once the client organisation has been consulted to a degree that the rules have been abstracted to a sufficient level, then the developer has no choice but to place the ball in the user's park. The user must be offered questions, and questions which elucidate the issues rather than confuse. Where there are key concepts conveyed in questions, the user must be alerted to their presence, or it will be entirely possible to miss them altogether. If we assume that the end-user is an expert in the subject area, then the system will be of little value. A much safer assumption is that such a user (such as a clerk in a government department) knows too little, and must be led through the process, and assisted, at every stage. Most large organisations have problems with providing sufficient resources for training to the levels which they would like to see. Sometimes it is simply lack of resources. At other times it is because staff turnover does not allow sufficient time for people in that position to be trained to the level of expertise required of them.
But no system - whether human or computer based - can afford to work with the image of the little worker ants mechanically providing data to the expert system. Such a system must incorporate an interactive process. The system guides the user and the user's responses dictate what further action should be taken by the system. The more guidance that can be provided to the user by the system, the better. Equally, those issues which are not capable of mechanised resolution must be left to the user. However, in leaving issues to the user, they can still be given some orientation. One way to ease the user into answering questions is to provide them with some understanding of the basis for the questions. If the user can easily see the motivation behind the question, then they will be considerably more at ease than if they are presented with a blank screen in the middle of which is the question "Did Mr Magoo's injury result from medical treatment?".
One solution to such problems is to incorporate text which sits alongside the questions posed by the system. At least two views are essential:
The source legislation which the user is investigating with the help of the expert system. If it is apparent what the questions are in response to, then the user may be able to discern relevance and will feel more able to judge significance. Being able to directly view the source legislation which they are supposed to be applying is one more piece of contextual information which helps with orientation (See Diagram 5). Commentary on the questions contained in the system. In addition to the source documents themselves, there will often be keywords or phrases in the questions put to the user which are not susceptible to interpretation through rules. Equally, there may be a particular approach to answering a line of questions which cannot be expressed in terms of rules - the tacit knowledge which we spoke of earlier. There is no option, for these sorts of issues, but to assist the user in what is essentially a human judgement. The best way to communicate these ideas at the appropriate time is to include context-sensitive commentary with every question posed to the user. As in the specification of the rules applied by the system, this commentary could well be of enormous proportions. One way to cut it down to size is to recognise that the system is not providing the interpretation, or every interpretation but just the client organisation's interpretation of the relevant provisions. In fact, it is usually the client organisation who bears the responsibility for writing such commentary (See Diagrams 1 and 3).
To date, much of the literature on expert systems has referred to concepts which are "open textured", to indicate that such issues cannot be resolved through the use of rules. Sometimes, as we have shown in the earlier articles, the other writers have assumed that this problem only arises in "marginal" areas. By contrast, we accept that language itself is incurably "open textured" in the sense that the expression of concepts in natural language, and the interpretation of these concepts is a subjective process which always gives rise to many possible meanings. However, we can limit the extent of the problem by adopting a particular point of view (the client organisation's). Otherwise, we must squarely face the issue of multiple possible interpretations and either develop strategies which will enable us to choose between them, or else incorporate all of them. Neither of these two options appear to be tractable except in the way we suggest. By taking a position, two things are possible:
1. We can actually arrive at a set of rules which dictate the process to be followed and the logic to be applied.
2. We can limit the range of issues which must be dealt with in the commentary assistance.
Given the need to provide text for the user, it would be possible to include standard or "flat" text alongside the knowledge base queries. However, there are several distinct benefits which can be gained from using hypertext:
Especially where a hypertext research system has been constructed for the organisation, the hypertext can be re-used wherever it is needed. Once the material is in the electronic form, it can be processed and used in very flexible ways. For example, portions of the legislation can consulted by the legal advisors or included in letters to individual clients and outside organisations. Hypertext is very well suited to the electronic presentation of information, particularly the on-screen presentation. As the tool is designed for use on-screen, hypertext material is usually formatted better for presentation in that format than standard flat text such as that derived from the electronic version of the book or article. For example, the hypertext developer knows that a line may run across the full screen or it may take up only a small portion of the screen if several windows are open at once. Therefore, they would be less likely to use centred headings. All of the facilities of the hypertext retrieval system become accessible directly from the expert system. Navigation through complex material, backtracking, history functions, etc. are only a mouse-click away from the user. Since hypertext can be traversed very easily, the textual assistance in the expert system can provide a starting point for investigation of the relevant source material. In this way the textual support is more than just a piece of text to help users out, but a starting point for a whole chain of legal research.
When hypertext is used in this fashion, there are several issues which arise in its construction. These derive mainly from the fact that the text written to accompany the expert system will be at a very low level of granularity. In other words, it will be very detailed, and will deal with some of the meaty issues at the core of the source legislative material.
Firstly, the developer must allow for the fact that the hypertext can be used in very flexible ways. It can either form part of the expert system, part of the overall research system, or may even be distributed by the organisation to outside people. One of the advantages of electronic text presentation is the flexibility of the electronic medium. Text is no longer tied to one page in one book, but is an information resource as much as any normal database.
Secondly, the textual support is vital to the operation of the expert system. It gives a very tight focus to analysis of the source text. The context of the knowledge base question which is supported by the hypertext can be used to focus the skills of the person writing the text. This is different to the situation where a group of people are assigned to write a policy manual without clearly analysing the issues presented by the source material first.
Finally, much of the meaning of the system to the end-user is captured in the commentary material which accompanies each question. A series of knowledge base questions, of themselves, have very little context and need something to tie them into the real world. Hypertext screen assistance fulfils this role. It is one way in which the developer can put themselves in the shoes of the ultimate knower - the user of the expert system. In an important sense, the hypertext becomes a tool for communicating in the subjective medium of language. The text writer attempts to communicate a particular approach, idea or concept to the end user of the system.
The key to this whole approach is that the client organisation is central to the process of modelling the legal knowledge. This is where the shift in emphasis from previous approaches which purport to model "objective" knowledge becomes significant. They system could not be said to provide objective assistance with answering a legal issue. However, it could be said to provide assistance consistent with the particular client organisation's point of view.
One of the reasons why many previous systems have not articulated this sort of approach, even if the developers have tried to follow it, is that can be difficult to involve the client's experts in the process where they have little knowledge of computers, less still of expert system construction - the black box effect. This can be resolved to a large extent if the knowledge representation scheme used by the developer is open to scrutiny by those not well versed in the computing sphere. In the legal sphere, this ideal requires a natural language representation, which is transparent and allows the domain experts of the client to verify the knowledge base.
In addition to being consulted as part of the process of knowledge base construction, it is the experts of the client who should have primary responsibility for the accompanying hypertext assistance. While the developer may actually put together the hypertext system, the text which goes into the system should ideally come directly from the client's domain experts. In this fashion, another level of meaning is added in accordance with the client's point of view.
Since the focus of this paper is the link between an expert system and a hypertext system, the example used here will be one of the expert components of the decision support system which links to the legal research system described above.[42] This component of the system, known as Claim for Cover, seamlessly links to the hypertext system, and is described in detail elsewhere.[43]
The overall structure and focus of the legal knowledge base will be summarised here. For the purposes of our discussion, we will briefly examine the three main types of substantive rule which were modelled in the application:
"Legal rules", which are the encoding of the Act as it is applied by the administering organisation,
"Interpretative rules", which model some of the interpretative decisions made by the organisation,
"Business rules" which are the organisational rules for processing claims.
For every type of rule, the knowledge modelling occurs through close work with domain experts of the client. No matter which type of rule is being articulated, inconsistencies and ambiguities are always resolved through reference to the owner of the system: the client organisation. All of the rules were modelled using STATUTE Expert, an expert system development environment produced by SoftLaw Corporation. This environment allows rules to be modelled as full English statements rather than by the use of symbolic logic.[44]
The issues which arise in the modelling of legal rules in a form which a computer can operate on is dealt with in a previous article.[45] In total, the knowledge base used by the system is composed of well over 5000 rules. Many of these rules consist of a verbatim model of the core provisions of the legislation. A verbatim model is a model of the legislation which uses the exact words of the legislation as far as possible.[46] The major legal issues dealt with by the system are:
Whether the injured person is entitled to cover under the Act,
Whether the injured person's injury may be classified as a work injury,
Which fund should be used to pay for the compensation associated with the injury,
The threshold of the insurance system is the concept of cover for an injury. If an injury is covered under the Act, then all medical fees, treatment fees, related costs and compensation can be paid in respect of the injury. If the injury is not covered, then none of this money is available. Since it is a threshold question, every claim is tested to see whether the injury claimed is actually covered under the Act. All of these claims are processed using the Claim for Cover module.
The rules for determining cover are contained in the legislation, and the Claim for Cover module is modelled very closely around the relevant provisions. Basically, for an injury to be covered under the act, it must satisfy the following criteria:
it must be a personal injury as laid out in the Act,
it must satisfy one of the specific categories of injury for which cover will be granted under the Act,
it must occur in a period to which the Act applies,
it must occur in a location to which the Act applies.
A special class of injuries are those which occur "out of and in the course of employment". Whether an injury can be classed as a work injury or not has significant implications
• for the account which the money for the injury will be drawn from, and
• as employers are experience rated, based on the number of work injuries which employees incur in the course of their employment.
Fund
The money to pay for the scheme comes out of taxes, motor vehicle insurance, premiums levied on medical practitioners, and premiums levied on employers and the self-employed. There are five funds set up from which to draw money, and rules specifying which accounts should be used depending on the circumstances of the injury. The amounts levied on the various groups will depend on the extent to which the fund is used. The funds are:
The employers account, primarily for work injuries.
The earners account, which mainly deals with injuries occurring to the self-employed.
The motor vehicle account, for injuries which are related to motor vehicle accidents.
The medical misadventure account, for injuries arising out of medical treatment.
The non-earners or supplementary account which will be used if none of the other accounts are appropriate.
One of the provisions of the Act reads as follows:
Cover under this Act shall extend to personal injury which:
(a) Is caused by an accident to the person concerned; or
(b) Is caused by gradual process, disease, or infection arising out of and in the course of employment as defined in section 7 or section 11 of this Act; or
(c) Is medical misadventure as defined in section 5 of this Act; or
(d) Is a consequence of treatment for personal injury.
This provision was modelled in the rulebase for Claim for Cover as follows:
|
The injured person's injury is covered if:
option 1:
The injured person's injury was caused by an accident to the injured
person;
option 2:
The injured person's injury was caused by gradual process, disease or
infection arising out of and in the course of employment as
defined in sections
7 and 11;
option 3:
The injured person's injury is medical misadventure as defined in section
5
option 4:
The injured person's injury is a consequence of treatment for personal
injury which is covered by the Act
If all the options of this rule are disproved, then it will be concluded
that the injured person's injury is not covered
|
As can be seen from the example, the representation captures two things:
The logic of the legislative provision. Each option is one way to prove that the person is covered, corresponding to paragraphs (a) to (d) of the subsection. The system can conclude that the person is not covered if each option is proved false. The language of the legislative provision. In so far as is possible, the language of the legislation is modelled verbatim in the rule.[47]
Because the rules are expressed in English, both the logic and the language used in the rulebase could then be checked by the client organisation to ensure that it was consistent with their point of view. In fact, while the system was being developed, key policy people from the client organisation were specifically given the task of validating the rulebase to guarantee that it was consistent with their view of the legislation. The responsibility for the interpretation of the legislation modelled in the rulebase fell squarely on the shoulders of the organisation. Not only is this within the limits of current rule-based technology, this is what they desired as a client.
Since the application is designed for one client organisation, it is the client's point of view which is implemented in the expert system. The system could not be said to objectively decide the legal issues for which it provides decision support. In addition to deciding the logic embedded in the legislation, the client will often need to go beyond the legislation and interpret a particular provision where its meaning cannot be resolved purely from the text of the legislation and the client's view of that text. Sometimes, the interpretative approach desired can be modelled as rules.
Hence, the knowledge bases also contain interpretative rules. These rules force users to adopt a certain approach to given legislative provisions. For example, under one section of the Act, where an injured person suffered an injury prior to 1 July 1992 and has previously lodged a claim prior to that date, then the issue of cover under the Act depends on whether they would have been covered under the old Acts. There is no specific guidance on what it means to have "lodged a claim", but the client determined that this must be interpreted as follows:
The claimant had previously lodged a claim for the injury if:
there was a record of the claim being registered on a mainframe system previously used to keep track of claim for cover, or
there was some record of the Corporation accepting the claim since 1 December 1989; or
the injured person had provided proof that the injured person received treatment from the injured person's General Practitioner for this personal injury; or
the injured person previously lodged a claim on the organisations current mainframe database, but the claim has now been deleted from computer records (a list of these "deleted" claims was maintained by the organisation).
This rule was modelled as follows:
|
The injured previously lodged a claim for the current injury if:
option 1:
There is a record of this claim being registered on the old mainframe
option 2:
There is some record of the Corporation accepting this claim since 1
December 1989
option 3:
The injured person has provided proof that the injured person received
treatment from the injured person's General Practitioner for
this personal
injury
option 4:
The injured person previously lodged a claim that has now been deleted from
the mainframe computer records
If all the options of this rule are disproved, then it will be concluded
that the injured person did not previously lodge a claim
for the current
injury
|
The user is also guided by the client organisation's interpretative decisions through the hypertext assistance which is provided to the user whenever they are asked a question or given the opportunity to input data. This forms the commentary assistance described above, and provides guidelines on how to approach questions asked by the system, where such guidelines cannot be modelled as interpretative rules (See diagrams 1 and 3).
Once again, the client was central to the creation of these interpretative rules. It is easier to see that this is the case with respect to interpretative rules, since they did not come from the source documents, but directly from the client's domain experts. It is a subjective point of view which drives the modelling process.
In addition to the legal and interpretative rules described above, the knowledge base contains many "business rules". Any large organisation must define how its own business will operate. In order to facilitate the operation of the business, the organisation will set up procedures so that cases are not dealt with in an ad hoc fashion, but are methodically and consistently handled. The organisation will provide a set of rules which dictate how its business will be carried out. In the application of the legal rules to specific real-word situations, this set of rules will have a substantial effect. The main factors accounted for in the business rules are how to go about the collection of relevant information, criteria governing the time in which a decision must be made, and criteria for determining whether the user has the authority to make a decision on the particular issue before them.[48]
For example, in determining whether a given user has the authority to determine a case, there are several relevant factors:
Whether a decision has previously been reached and confirmed concerning the claim. If a decision has previously been made, and the current investigation is a reassessment, then this will usually entail a much higher level of authority.
Whether the decision is a decline or an accept. Generally decisions to decline cover or to disentitle the injured person from receiving payment require a higher level of authority than decisions to accept cover. This is partly because the Act is very strict about information requirements for decline decisions, and partly because people are more likely to appeal the decision if they are declined cover.
What class of injury the claim falls under. For more complicated cases involving injury by gradual process, disease or infection, claims for injury by medical misadventure, and claims for mental injuries, then a higher level of authority is usually called for.
Hence some of the top level business rules read as follows:
|
The user has the delegation to confirm the decision if:
option 1:
The current user's decision is not a reassessment; and
The user has the delegation to confirm the original decision
option 2:
The current user's decision is a reassessment; and
The user has the delegation to confirm the reassessment decision
If all the options of this rule are disproved, then it will be concluded
that the user does not have the delegation to confirm the
decision
|
|
The user has the delegation to confirm the original decision if:
option 1:
The injured person's injury is covered under the Act; and
The injured person is not covered by any of the disentitling provisions
investigated as part of the consideration of cover; and
The user has the delegation to confirm the original decision to accept the
claim for cover;
option 2:
The injured person's injury is not covered under the Act; and
The user has the delegation to confirm the original decision to decline the
claim for cover
option 3:
The injured person's injury is covered under the Act; and
The injured person is covered by one of the disentitling provisions
investigated as part of the consideration of cover; and
The user has the delegation to confirm the original decision to disentitle
the client from receiving payments .
If all the options of this rule are disproved, then it will be concluded
that the user does not have the delegation to confirm the
original
decision
|
In the same way we have previously seen, all of the rules were verified by the client as part of the process of rulebase construction, quite apart from any standard system testing which was done of the application as a whole. These business rules have no direct relationship with the source documents. However, they are a necessary part of the system because they allow the abstract legislation to be applied to real cases, and provide the client with procedures and rules for the manner in which claims must be investigated. As with both the interpretative and legislative rules which form the rest of the knowledge base, the process of knowledge modelling is driven by the client's subjective viewpoint.
Using standard expert system functionality, reports are automatically generated by the system explaining reasons for decisions and listing the questions answered by the user. At any stage users can re-trace their steps, or receive an explanation of why they are being asked a particular question. Rule-based facilities are also used to generate standard letters to clients.
The key benefits offered by such a system come from its handling of business process and logical complexity in the manner described earlier. Instead of having to pass through numerous extraneous people, the business process may be streamlined by the use of the expert system. All of the requisite information collection, delegation levels and communication can occur when the claim is processed. This reduces administrative overheads as well as the risk of error.
Equally, the end user need not have a detailed understanding of the whole body of legislation. If the analyst has done the job properly, the end user can concern themselves with the more discrete language issues which arise in relation to the particular case before them. The client sees the benefit here because decisions are necessarily more consistent with the point of view implemented by the analyst in conjunction with the client's own people. While the user makes the end decision, they are much less likely to overlook issues or consider irrelevant material. They could still abuse the system by erroneously answering valid questions, but this would be no different in a manual system - just harder to pick up. With an automated system, there is a record of decisions, which will allow for decision trails to be audited subsequently. This substantially assists with management control of the decision-making process.[49]
The hypertext is directly included in the expert system in two ways:
Displaying commentary material to assist users with the language used by the knowledge base (see Diagram 3).
Displaying the source legislation for the question asked by the system.
As with every other part of the information system, the process of creating the policy text was driven by the client. It was the client's domain experts who had responsibility for writing the text which accompanied any knowledge base question. Their own point of view was captured, rather than a supposedly "objective" determination that the words used in the legislation or policy had particular meaning.
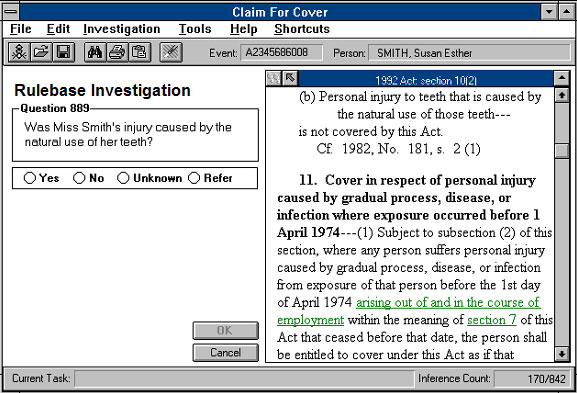
The following screen capture illustrates a standard question screen with the source material shown on the right. Where commentary assistance is displayed, the question screen remains the same, but the hypertext window on the right contains the commentary instead of the legislation. Once again, the light underlined words are hotwords which appear in green on the screen.
Diagram 5: Decision Support System with Source Legislation Displayed in Hypertext
The main conclusion to be derived is that it is in fact possible to create useful and useable information systems in the legal sphere. These information systems can be based on hypertext, or a mixture of hypertext and expert systems technology.
However, the process of arriving at a consistent, coherent and accurate knowledge base intimately involves consultation with someone to provide a subjective point of view. This is much more likely to be the case if the system is built for a particular client organisation, and captures their point of view. In such a situation, it is possible to narrow down the world of language sufficiently to model legal, interpretative and business material.
Another key to achieving a useful knowledge base is the use of hypertext to augment queries asked by the system. In this sense, the system can almost be seen as a path through the volumes of material which can be captured in a hypertext system. The expert system directs the user where to go, and what issues to address. The hypertext actually provides much of the thought behind the issues. In this way, an appropriate balance may be struck between user discretion and computer automation.
The shift in emphasis from the position of those who we have taken issue with to our own position is that we have been advocating the development of information systems which articulate a subjective viewpoint. Instead of searching for objective meanings - a grail which is unattainable - a more informed approach can yield positive results. Rather than avoiding the issue of meaning, this approach places responsibility for decisions about meaning squarely on the shoulders of identifiable individuals who are accountable for them. Instead of avoiding the issue of the knower and the known, we try and establish who and what they are and work within that framework.
[1] BSc. LL.B. (Hons) (ANU) Legal Analyst Softlaw Corporation Pty Ltd, Barrister of the Supreme Court of New South Wales.
[2] ACII LL.B. (Hons) (Belfast) PhD (Edinburgh) Senior Lecturer in Law at the Australian National University.
[3] The first article which we refer to in this section is Moles RN "Logic Programming - An Assessment of its Potential for Artificial Intelligence Applications in Law" (1991) Journal of Law and Information Science Vol 2 No 2 pp 137-164. The second article referred to here is Moles RN and Dayal S "There is More to Life Than Logic" Journal of Law and Information Science (1992) vol 3 no 2 pp 188-218.
[4] Bob Moles is currently working with Bibi Sangha (Flinders Law School) on an analysis of the important recent case of Diprose v Louth [1990] 54 SASR 438. The judge's determination of the "facts" in this case is being considered in the light of the transcript of the evidence and other background material to illustrate the highly creative nature of the "fact finding". Particularly interesting are the gendered assumptions which the judge works with, and which influences fact finding, but are not themselves, factually based.
[5] Morris G, Cook C, Creyke R and Geddes R, Laying Down the Law (3rd ed 1992) Butterworths p37.
[6] Morris G, Cook C, Creyke R and Geddes R, Laying Down the Law (3rd ed 1992) Butterworths pp 43-45.
[7] Zeleznikow J and Hunter D "Rationales For the Continued Development of Legal Expert Systems" (1992) Journal of Law and Information Science Vol 3 No 1 pp 94-110
[8] Stamper, R "Signs Organisations and Norms" Keynote Address: Australian National Information Systems Conference (October 1992) and Stamper R "The Role of Semantics in Legal Expert Systems and Legal Expert Reasoning" (1991) 115 Ratio Juris Vol 4 No 2 pp 219-244 at p 237 both of which were discussed in our second article.
[9] Zeleznikow J and Hunter D "Rationales For the Continued Development of Legal Expert Systems" (1992) Journal of Law and Information Science Vol 3 No 1 pp 94-110 at p 100.
[10] Susskind R Expert Systems in Law (1987) Oxford University Press, p 53, where he suggests that the chosen domain should be relatively autonomous or self contained. He suggests that corporate tax would be inappropriate as this would involve company law, corporation tax, VAT and personal tax. This would be too large a range for an expert system. The Scottish law of damage caused by animals, on the other hand, represents a small and identifiable aspect of delict.
[11] Weizenbaum J Computer Power and Human Reason (1976) WH Freeman and Co pp 2-8.
[12] The references to Stamper can be found in the author's second article, referred to above, and to Polanyi see Personal Knowledge (1962) Routledge & Kegan Paul "In any case, every use of language to describe experience in a changing world applies language to a somewhat unprecedented instance of its subject matter, and thus somewhat modifies both the meaning of language and the structure of our conceptual framework" p 104.
[13] See for example Harris V "Artificial Intelligence and Law - Innovation in a laggard market?" (1993) Journal of Law and Information Science 287, at p.287 footnote 1, where the author even traces the distinction back to the work of Mehl Automation in the Legal World in Mechanisation of Thought Processes (1959).
[14] Di Giorgi RM and R.Nannucci R "A Legal Hypertext System Prototype". In: Grutters CAFM., Breuker JAPJ, van den Herik HJ, Schmidt AHJ and de Vey Mestdagh CNJ (eds) Legal Knowledge Based Systems: Information Technology & Law, JURIX'92 (1992), Koninklijke Vermande, Lelystad NL at p.172.
[15] For a description and discussion of the key facets see Greenleaf G, Mowbray A and Tyree A "The Datalex Legal Workstation - Integrating Tools for Lawyers" (1993) Journal of Law and Information Science p. 219. This system was based on an earlier system produced by Johnson P and Mead D in 1985.
[16] See for example Widdison, Pritchard and Robinson "Expert System Meets Hypertext: The European Conflicts Guide" (1993) Journal of Law and Information Science p. 82.
[17] Susskind R Expert Systems in Law (1987) Oxford University Press, pp 52-58.
[18] For example, Susskind's own Latent Damage System, produced with Phillip Capper which accompanies Susskind R and Capper P Latent Damage Law - The Expert System (1988) Butterworths.
[19] Susskind R Expert Systems in Law (1987) Oxford University Press, p43.
[20] See chapter 16 of Bench-Capon TJM (Ed.) Knowledge Base Systems and Legal Applications (1991) Academic Press.
[21] For example, see Stamper R "The Role of Semantics in Legal Expert Systems and Legal Reasoning" (1991) Ratio Juris pp. 219 - 244, at pp. 229 - 232.
[22] See the history provided in Smith and Weiss "Hypertext" (1988) 31 Communications of the ACM p. 816.
[23] See Greenleaf, Mowbray and Tyree "The Datalex Legal Workstation - Integrating Tools for Lawyers" (1993) Journal of Law and Information Science p. 219, at pp223 -4 and associated references.
[24] For more detail see Chapter 1 of Schneiderman and Kearsley Hypertext Hands-On! (1989) Addison-Wesley, or Afrati and Koutras "A Hypertext Model Supporting Query Mechanisms" and "Browsing in Hyperdocuments with the Assistance of a Nerual Network", in the ACM electronic release of hypertext papers from Hypertext 1991.
[25] Di Giorgi, R.M. and R.Nannucci, A Legal Hypertext System Prototype. In: Grutters CAFM., Breuker JAPJ, van den Herik HJ, Schmidt AHJ and de Vey Mestdagh CNJ (eds) Legal Knowledge Based Systems: Information Technology & Law, JURIX'92 (1992) Koninklijke Vermande, Lelystad NL at p.173.
[26] For example Greenleaf, Mowbray and Tyree "The Datalex Legal Workstation - Integrating Tools for Lawyers" (1993) Journal of Law and Information Science p. 219, at p.227.
[27] For example, some of the entry points to the Legal Research System described below. For a discussion of the relative benefits of conceptual retrieval versus free text searching, see Wildemast CAM and de Mulder RV "Some Design Considerations for a Conceptual Legal Information Retrieval System". In: Grutters CAFM., Breuker JAPJ, van den Herik HJ, Schmidt AHJ and de Vey Mestdagh CNJ (eds) Legal Knowledge Based Systems: Information Technology & Law, JURIX'92 (1992) Koninklijke Vermande, Lelystad NL at pp.81 - 82.
[28] For example the early versions of the Datalex Workstation.
[29] See for example Hyperlaw, which was constructed using Hypercard, an Apple Computer product - Di Giorgi RM and Nannucci R, "A Legal Hypertext System Prototype". In: Grutters CAFM., Breuker JAPJ, van den Herik HJ, Schmidt AHJ and de Vey Mestdagh CNJ (eds) Legal Knowledge Based Systems: Information Technology & Law, JURIX'92 (1992) Koninklijke Vermande, Lelystad NL at p.173.
[30] Both the legal research system and the decision support system described below operate under the Microsoft Windows environment.
[31] See Wildemast CAM and de Mulder RV, "Some Design Considerations for a Conceptual Legal Information Retrieval System". In: Grutters CAFM., Breuker JAPJ, van den Herik HJ, Schmidt AHJ and de Vey Mestdagh CNJ (eds) Legal Knowledge Based Systems: Information Technology & Law, JURIX'92 (1992) Koninklijke Vermande, Lelystad NL at p.81. More generally see Greenleaf G, Mowbray A and Tyree A "The Datalex Legal Workstation - Integrating Tools for Lawyers" (1993) Journal of Law and Information Science p. 219.
[32] See Blair DC and Maron ME "An evaluation of Retrieval effectiveness for a full-text document-retrieval system". (1985) Communications of the ACM, vol. 28 no. 3, pp. 289 - 299.
[33] Wildemast CAM and de Mulder RV, "Some Design Considerations for a Conceptual Legal Information Retrieval System". In: Grutters CAFM., Breuker JAPJ, van den Herik HJ, Schmidt AHJ and de Vey Mestdagh CNJ (eds) Legal Knowledge Based Systems: Information Technology & Law, JURIX'92 (1992) Koninklijke Vermande, Lelystad NL at p.82.
[34] Greenleaf G Mowbray A and Tyree A "The Datalex Legal Workstation - Integrating Tools for Lawyers" (1993) Journal of Law and Information Science p. 219, p223.
[35] See diagram 3. The text on the right is provided using an embeddable STATUTE Hypertext object.
[36] This is quite small in terms of standard retrieval systems. For example, STATUTE Hypertext provides the medium for a hypertext research system currently used by the Australian Department of Social Security, where there is close to 20 megabytes of source material.
[37] See Greenleaf, Mowbray and Tyree "The Datalex Legal Workstation - Integrating Tools for Lawyers" (1993) Journal of Law and Information Science 219, at p.225 for a description of Hyper-spaghetti.
[38] For a comparison of desirable features see see Stylianou, Madey and Smith, "Selection Criteria for Expert System Shells" (1992) 35 Communications of the ACM Vol 10, pp.31 - 48.
[39] See Harris V "Artificial Intelligence and Law - Innovation in a laggard market?" (1993) Journal of Law and Information Science 287.
[40] Johnson P and Mead D "Legislative Knowledge Base Systems for Public Administration - Some Practical Issues" (1991) Proceedings of the Third International Conference on Artificial Intelligence and Law pp.108 - 117.
[41] For more detail see Johnson P and Mead D "Legislative Knowledge Base Systems for Public Administration - Some Practical Issues" (1991) Proceedings of the Third International Conference on Artificial Intelligence and Law pp.108 - 117.
[42] See Part II. Note that any decision support system which operates on a rule-based model of legislation could be used here. For example CCPS, the SoftLaw system under construction for the Australian Department of Veterans' Affairs, or OPAL, the SoftLaw prototype constructed for the Australiand Department of Social Security in the late 1980s.
[43] See Dayal S, Harmer M, Johnson P and Mead D "Beyond Knowledge Representation: Commercial Uses for Legal Knowledge Bases" in (1993) Proceedings of the Fourth International Conference on Artificial Intelligence and the Law at pp.167 - 175.
[44] For more detail see Dayal S, Johnson P and Mead D "Natural Language: An Appropriate Knowledge Representation Scheme for the Administrative Environment", forthcoming in Proceedings of the Second World Congress on Expert Systems, Lisbon Portugal, Jan. 1994.
[45] Johnson P and Mead D "Legislative Knowledge Base Systems for Public Administration - Some Practical Issues" (1991) Proceedings of the Third International Conference on Artificial Intelligence and Law pp.108 - 117.
[46] See the example legislative provision and the rule which models the provision shown below.
[47] For a detailed discussion of the problems which will be encountered if the language is not faithfully modelled, see Dayal S, Johnson P and Mead D "Natural Language: An Appropriate Knowledge Representation Scheme for the Administrative Environment", forthcoming in Proceedings of the Second World Congress on Expert Systems, Lisbon Portugal, Jan. 1994.
[48] See Dayal S, Harmer M, Johnson P and Mead D "Beyond Knowledge Representation: Commercial Uses for Legal Knowledge Bases" in (1993) Proceedings of the Fourth International Conference on Artificial Intelligence and the Law at pp.167 - 175.
[49] For this and other managerial benefits, see: Dayal S, Harmer M, Johnson P and Mead D "Beyond Knowledge Representation: Commercial Uses for Legal Knowledge Bases" in (1993) Proceedings of the Fourth International Conference on Artificial Intelligence and the Law pp.167 - 175 at p.175.
AustLII:
Copyright Policy
|
Disclaimers
|
Privacy Policy
|
Feedback
URL: http://www.austlii.edu.au/au/journals/JlLawInfoSci/1993/23.html